
h-indeks dikembangkan pada tahun 2005 oleh seorang fisikawan dari Universitas California San Diego bernama Jorge Hirsch. Tujuannya adalah membangun indikator komposit, di tingkat peneliti perorangan, yang akan mencerminkan produktivitas peneliti tersebut dan dampaknya pada dunia ilmu pengetahuan.
Perhitungan h-indeks ini cukup sederhana. Seorang penulis memiliki indeks h ketika ia telah menerbitkan makalah sejumlah h, yang masing-masing telah dikutip setidaknya h kali. Sebagai contoh, seorang penulis memiliki h-indeks 10, jika setidaknya sepuluh artikelnya telah disitasi setidaknya sepuluh kali per artikel atau 100 sitasi. Bila jumlah total sitasi dari sepuluh artikel tersebut hanya 50 maka h-indeks nya hanya 5.
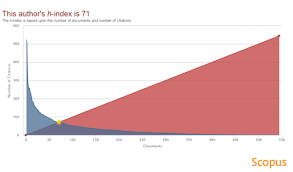
Karena kesederhanaan penghitungan h-indeks ini maka dengan cepat diadopsi dalam banyak disiplin ilmu, khususnya dalam ilmu alam dan teknik, sebagai indikator di mana kualitas seorang ilmuwan dinilai. Ini mengarah pada apa yang disebut gelembung-h, di mana beberapa peneliti dalam bidang sains dan lainnya bergegas untuk menggambarkan h-indeks untuk populasi yang berbeda dan membangun varian baru. h-indeks juga dimasukkan ke dalam basis data bibliometrik, sehingga mengkodifikasi penggunaannya.
Sementara h-indeks bertujuan untuk menyeimbangkan publikasi dan sitasi, pada kenyataannya publikasi adalah variabel yang lebih dominan dalam perhitungan, mengingat ia mewakili batas atas indeks, yaitu h-indeks seseorang tidak akan pernah lebih tinggi dari jumlah publikasinya. Di sisi lain, setiap sitasi tambahan yang membuat artikel yang disitasi lebih dari jumlah publikasi seorang penulis akan hilang dalam perhitungan. Contohnya, misal ada dua penulis, satu penulis memiliki sepuluh artikel yang masing-masing disitasi sepuluh kali, maka penulis ini memiliki h-indeks 10. Sedangkan satu penulis lainnya telah menulis lima makalah yang masing-masing dikutip 100 kali, maka penulis ini memiliki h-indeks 5, yaitu setengah dari penulis pertama meskipun setiap publikasi disitasi sepuluh kali lebih banyak.
Seperti yang ditunjukkan oleh contoh di atas, indikator ini juga rentan terhadap distorsi ilmiah dan sosiologis mengingat indikator ini lebih menyukai kuantitas dalam hal publikasi yang sangat dipengaruhi oleh senioritas, aktivitas kolaboratif, dan disiplin. Beberapa varian h-indeks lain telah diusulkan, banyak di antaranya telah mencoba mengatasi berbagai kelemahan indikator. Namun, kekhawatiran yang lebih memberatkan untuk indikator ini adalah bahwa ia tidak memiliki konsep yang mendasarinya. Produktivitas dan dampak adalah dua konsep yang terintegrasi (tergabung) dalam h-indeks. Namun, tidak jelas konsep apa yang diwakili oleh indikator komposit ini. Oleh karena itu, meskipun banyak varian telah diajukan, namun semuanya memiliki kelemahan yang sama seperti aslinya, yaitu penggabungan dua konsep menjadi satu indikator.
i10-indeks
i10-indeks mencoba mengatasi salah satu kelemahan h-indeks seperti pada contoh di atas, di mana h-indeks seseorang tidak akan pernah melebihi jumlah publikasinya. i10-indeks ini adalah jumlah artikel yang telah mendapatkan sitasi lebih dari 10 kali. Jadi, bila ada 15 artikel publikasi seseorang yang telah mendapatkan setidaknya 10 kali maka i10-indeks nya adalah 15, dan begitu seterusnya.

Dalam profil Google Scholar seorang penulis i10-indeks ini disertakan untuk melengkapi informasi total sitasi dan h-indeks. Informasi ini akan menjadi pelengkap dari salah satu kelemahan h-indeks. Paling tidak menjadi poin pembeda dalam hal jumlah sitasi. Berikut ini adalah contoh i10-indeks.
g-indeks
g-indeks adalah salah satu alternatif dari h-indeks. Indeks ini kali pertama diusulkan oleh Leo Egghe pada tahun 2006. Sama dengan h-indeks, g-indeks juga merupakan metrik sitasi di tingkat individu penulis. Namun, indeks ini dihitung berdasarkan distribusi sitasi yang diterima oleh publikasi/artikel seorang peneliti.
Tidak seperti h-indeks yang tidak memperhatikan rata-rata jumlah sitasi, g-indeks memungkinkan sitasi dari artikel yang dikutip lebih tinggi untuk mendukung artikel yang jumlah sitasinya sedikit. g-indeks dihitung berdasarkan distribusi sitasi yang diterima oleh publikasi seorang peneliti.
Bila seperangkat artikel atau publikasi seseorang diurutkan berdasarkan jumlah sitasi dari yang paling banyak sampai paling sedikit maka angka g-indeks adalah angka terbesar yang unik sehingga bagian atas dari batas g menerima setidaknya sebanyak g2 secara total. Dengan kata lain g adalah jumlah n artikel yang disitasi paling banyak dimana jumlah rata-rata sitasi minimal n.

Salah satu aplikasi yang menampilkan g-indeks ini adalah Publish or Perish. Gambar di atas adalah salah satu contohnya.

One comment