Salah satu asumsi yang harus dipenuhi dalam analisis statistik induktif adalah data yang digunakan terdistribusi normal. Mengapa demikian? Jawabannya mungkin tidak sederhana karena ceritanya bisa jadi panjang. Namun setidaknya saya akan berusaha menyampaikannya secara singkat.
Distribusi normal adalah bagian mendasar dari statistik. Secara matematis, distribusi frekuensi data suatu variabel dikatakan normal jika Mean = Median = Modus, atau paling tidak hampir sama. Distribusi ini merupakan alat yang sangat berguna untuk banyak disiplin ilmu.
Teorema Limit Sentral (Central Limit Theorem) menyatakan bahwa jumlah variabel acak independen cenderung ke arah distribusi normal, bahkan jika variabel awal tidak terdistribusi secara normal sekalipun. Jadi, normalitas adalah karakteristik alamiah dari setiap populasi penelitian. Ini adalah konsep kunci dari semua statistik inferensial dan teori probabilitas.
Pada setiap penelitian ilmiah yang menggunakan sampel, simpulan yang dihasilkan diharapkan dapat digeneralisasikan pada populasinya. Pengambilan sampel secara acak adalah salah satu jaminan bahwa simpulan ini dapat digeneralisasi.
Analisis regresi juga termasuk dari bagian statistik inferensial/induktif. Dengan demikian normalitas data yang digunakan juga menjadi asumsi yang harus dipenuhi, namun dalam analisis regresi ini kita tidak perlu melihat normalitas data dari setiap variabel yang digunakan. Kita hanya perlu melihat normalitas residual (error term) dari hasil penghitungan persamaan regresi yang telah kita lakukan.
Normalitas residual ini juga berguna untuk memastikan bahwa hasil/simpulan dari uji F (uji global) dan uji t (uji parsial) adalah valid. Dengan demikian dalam setiap analisis regresi idealnya residual yang dihasilkan terdisbusi secara normal, atau asumsi normalitasnya terpenuhi.
Untuk melihat apakah asumsi normalitas ini terpenuhi, kita perlu menyusun residual estimasi ini dalam sebuah distribusi frekuensi. Untuk memastikan residual tersebut terdistrubusi normal atau tidak kita bisa uji Jarque-Berra. Uji ini ditemukan oleh Carlos Jarque dan Anil K. Bera.
Rumus Jarque-Berra untuk data variabel berbeda dengan rumus Jarque-Berra untuk residual regeresi. Gambar 1. merupakan Rumus Jarque-Berra untuk menguji normalitas data setiap variabel yang digunakan dalam analisi regresi, sedangkan rumus pada Gambar 2. Adalah Rumus Jarque-Berra yang digunakan untuk menguji normalitas residual regresi. Rumus kedua merupakan modifikasi dari rumus asli (gambar 1).
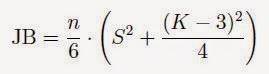
Gambar 1. Rumus Jarque-Berra Variabel
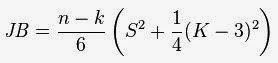
Gambar 2. Rumus Jarque-Berra Residual
Untuk memastikan terpenuhinya asumsi normalitas pada analisis regresi, kita cukup menguji normalitas residualnya saja. Bila normalitas residualnya terpenuhi maka bisa dianggap normalitas data seluruh variabel juga terdistribusi normal.
Untuk mengujinya kita perlu merumuskan hipotesis statistik serta kriteria ujinya terlebih dahulu.
Hipotesis:
Ho : residual terdistribusi normal
Ha : residual tidak terdistribusi normal
Kriteria Uji:
Ho diterima apabila X2 (chi-square) ≤ 2, atau nilai probabilitas lebih dari α (misalnya 5%).
Langkah pengujian normalitas residual regresi menggunakan gretl sangat mudah. Berikut ini adalah langkah-langkahnya:
- Buka jendela output model regresi Anda
- Pilih menu “Test” pada jendela output regresi
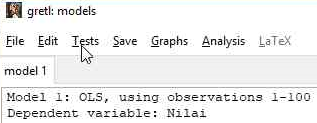
- Lanjutkan dengan memilih “Normality of residual” seperti pada gambar di bawah ini
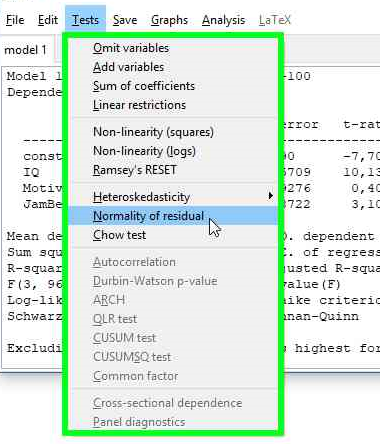
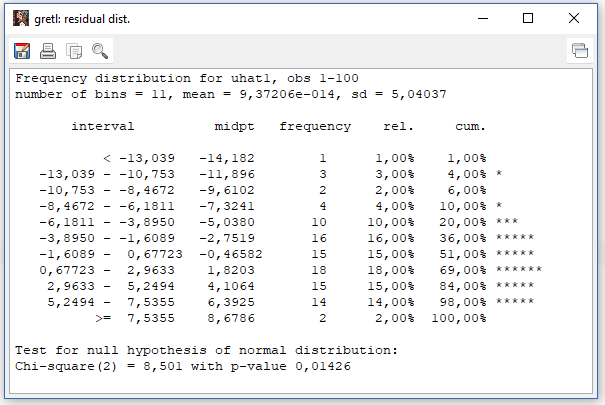
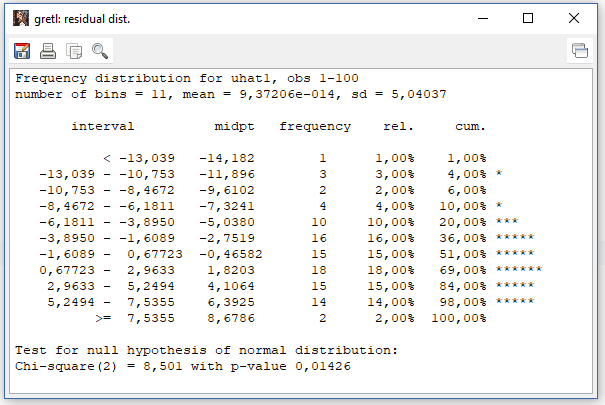
- Seketika akan muncul hasilnya yang terdiri dari dua jendela sekaligus. Jendela pertama adalah tabel distribusi frekuensi dengan interval data yang sudah otomatis dibuatkan oleh gretl
- Jendela kedua adalah histogram dari distribusi fekuensi residual
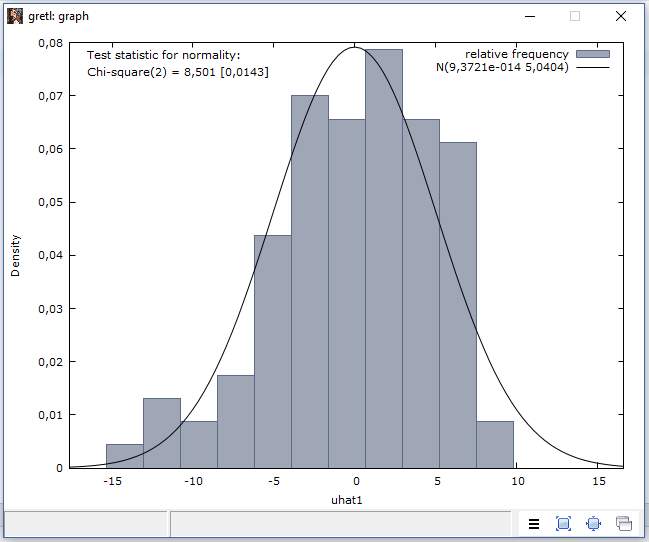
- Dalam kedua output tersebut sama-sama ditampilkan nilai X2 (chi-square) dan nilai probabilitasnya.
Hasil tes normalitas residual tersebut menghasilkan nilai X2 sebesar 8,501 sehingga kita harus menolak Ho (residual terdistribusi normal), otomatis nilai probabilitasnya juga lebih kecil dari 0,05 yaitu sebesar 0,0143. Dengan demikian kita wajib menoloak Ho dan sebagai konsekuensinya harus menerima Ha yaitu residual tidak terdistribusi normal.
Berdasar hasil pengujian tersebut maka asumsi normalitas residual tidak terpenuhi. Tidak terpenuhinya asumsi normalitas ini akan menimbulkan konsekuensi, nilai prediksi yang diperoleh akan bias dan kurang bisa dipercaya.
Sekali lagi bila tujuan kita adalah untuk mencari model prediksi terbaik dan memang tujuannya adalah memprediksi Y seakurat mungkin maka perlu ada langkah-langkah treatment. Ada beberapa langkah untuk mengatasi masalah asumsi normalitas ini. Langkah-langkah tersebut diantaranya adalah sebagai berikut:
1. Melakukan Re-Sampling menggunakan Metode Bootstrap atau Metode Jacknife
Metode bootstrap adalah metode berbasis resampling data sampel dengan syarat pengembalian pada datanya dengan harapan sampel tersebut mewakili data populai sebenarnya. Biasanya ukuran resampling diambil sebanyak ribuan kali. Bootstrap memungkinkan kita untuk melakukan inferensi statistik tanpa asumsi distribusi yang kuat.
Selain metode bootstrap ada satu lagi metode resampling yang dapat kita gunakan, yaitu metode jacknife. Metode ini hampir sama dengan bootstrap, karena sebenarnya bootstrap adalah modifikasi dari jacknife namum menghilangkan satu per satu observasi, dilakukan berulang sampai (n-1) kali dan mencari taksiran parameter dari rata-rata parameter (beta) setiap kali resampling dilakukan.
Dengan demikian tidak terpenuhinya asumsi normalitas residual tetap bisa kita lakukan dengan metode bootstrap atau jacknife. Namun umumnya aplikasi statistik hanya menyediakan metode bootstrap.
2. Menambah Jumlah Data
Solusi lain yang bisa kita lakukan adalah dengan menambah jumlah data atau observasi. Ketika jumlah data ditambah maka akan mengakibatkan nilai residual yang memiliki nilai ekstrim akan berkurang, karena dengan semakin banyaknya jumlah data maka pembagi nilai ekstrem akan semakin besar sehingga nilai rata-ratanya akan mendekati nilai tengahnya.
3. Melakukan transformasi data menjadi Log atau LN
Dengan melakukan tranformasi data variabel maka selisih data nilai terbesar dengan nilai terkecil akan terpangkas. Dengan demikian data yang memiliki nilai ekstrem akan semakin mendekati nilai rata-rata.
4. Menghapus data yang ekstrim
Cara mengatasi ketidaknormalan residual selanjutnya adalah dengan menghapus data yang ekstrim atau dianggap sebagai penyebab tidak normalnya residual. Cara ini akan membuat data semakin mendekati nilai rata-rata. Namun bilamana jumlah data sampel terlalu kecil maka cara ini tidak direkomendasikan.

One comment