
Skor standar (Z) adalah angka yang merupakan perbedaan antara nilai data dan rata-rata, dibagi dengan standar deviasi. Bila dituliskan rumusnya sebagai berikut:
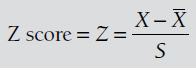
Z-score juga sering disebut dengan nilai baku atau nilai standar. Z-score dapat digunakan untuk membantu menentukan apakah sebuah data bernilai ekstrem, atau outlier. Data outlier adalah data yang bernilai jauh dari rata-rata. Aturan umumnya adalah Z-score dengan nilai kurang dari –3 atau lebih dari +3 menunjukkan bahwa nilai data adalah nilai ekstrem.
Sebagai contoh, kita bisa menggunakan data berikut ini.
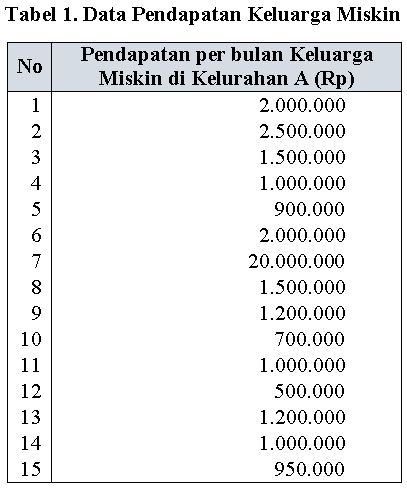
Bila kita hitung nilai Z-score diperoleh hasil sebagai berikut:
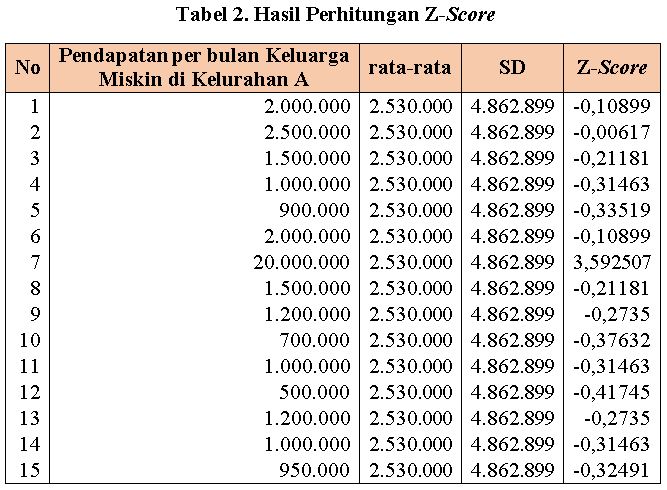
Tabel perhitungan tersebut dilakukan di Ms Excel, bila menggunakan SPSS akan mengasilkan output sebagai berikut:
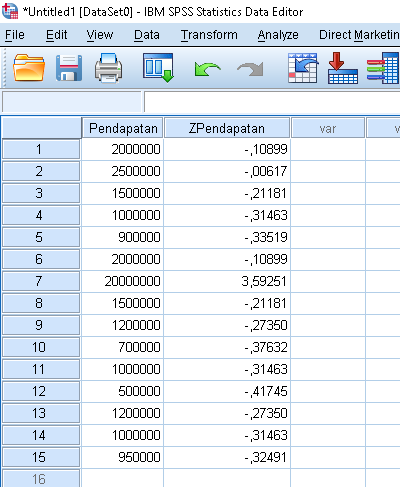
Pada data nomor 7 nilai Z-score adalah 3,59. Nilai ini lebih besar dari 3, sehingga kita bisa mengatakan data tersebut adalah outlier. Data outlier bisa disebabkan oleh beberapa hal, misalnya surveyor salah dalam menentukan responden, kondisi responden yang sudah berubah, atau bisa karena kesalahan input (pengetikan).
Dalam analisis regresi nilai Z-score bisa kita gunakan untuk menghitung nilai koefisien pengaruh (Path Analysis). Hal ini bila kita ingin mengetahui kekuatan pengaruh dari tiap-tiap variabel X yang mempunyai satuan tidak setara. Misalnya dalam contoh data pada tabel 3. Data ini sudah sering saya gunakan pada artikel-artikel terdahulu hanya saja untuk kali ini menggunakan satuan asli.
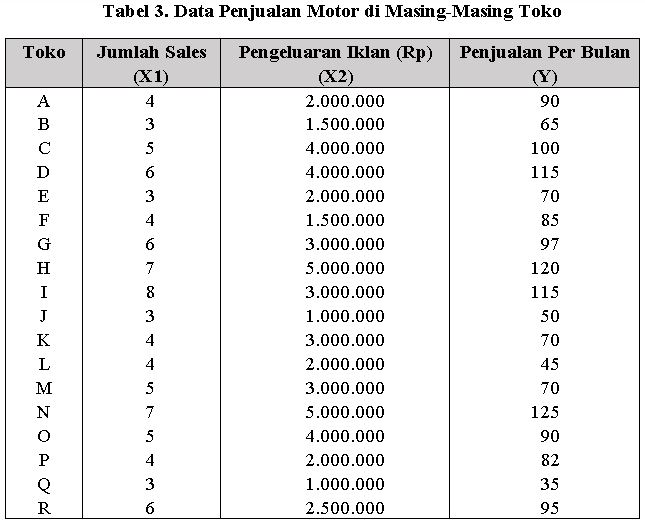
Bila kita diminta untuk menganalisis kekuatan pengaruh variabel Jumlah Sales dan Biaya Iklan terhadap Penjualan Motor, maka hasil output regresi yang akan kita peroleh tidak akan menggambarkan kekuatan pengaruh masing-masing variabel independen bila kita tidak melakukan transformasi data menjadi Z-score. Seperti kita lihat pada tabel 3. dimana satuan jumlah sales dan satuan biaya iklan sangat jauh berbeda. Jumlah sales memiliki satuan jumlah orang, di data tersebut nilai maksimalnya adalah 8. Sedangkan, satuan biaya iklan adalah Rupiah yang mencapai jutaan.
Bila data tersebut langsung dianalisis menggunakan Analisis Regresi, dengan persamaan regresi sebagai berikut:
Y = a + b1 X1 + b2 X2 + e
Maka akan mendapat output sebagai berikut:
Y = 16,77 + 9,72 X1 + 0,0000075 X2 + e
Nah, bisa kita lihat dari output di atas perubahan nilai X1 satu satuan akan menambah Y sebesar 9,72 dan penambahan nilai X2 satu satuan akan menambah nilai Y sebesar 0,0000075 X2. Hasil ini akan berguna bila kita berusaha untuk mengestimasi nilai Y. Namun, bila kita ingin mengetahui kekuatan pengaruh masing-masing variabel terhadap Y maka ini menjadi sangat timpang.
Jadi, kita butuh mentransformasi setiap data menjadi Z-score sehingga koefisien regresinya menjadi setara. Sehingga persamaannya menjadi seperti di bawah ini.
ZY = P1 ZX1 + P2 ZX2 + e
Sebelum menghitung koefisien regresi standardized kita harus mentransformasi data ke satuan baku (Z-score). Berikut hasil transformasinya:
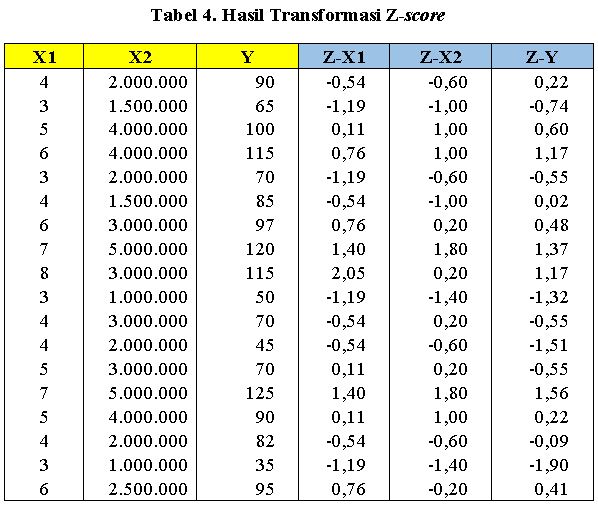
Kita bisa melihat, setelah dilakukan transformasi data menjadi Z-score maka setiap nilai dari masing-masing variabel tersebut menjadi setara dimana nilai minimalnya adalah -3 dan maksimalnya adalah +3. Nah, bila kita hitung regresinya akan menghasilkan output sebagai berikut:

ZY = 0,576 ZX1 + 0,360 ZX2 + e
Dari hasil tersebut kita bisa menyimpulkan besaran pengaruh dari masing-masing variabel independen. Hasil tersebut bisa dijadikan dasar bahwa pengaruh jumlah sales lebih besar bila dibandingkan dengan pengeluaran iklan.
Bila kita menggunakan Perangkat Lunak SPSS, kita tidak perlu susah-susah melakukan transformasi Z-score karena output regresi SPSS sudah menyediakan output regresi unstandardized dan standardized sekaligus.
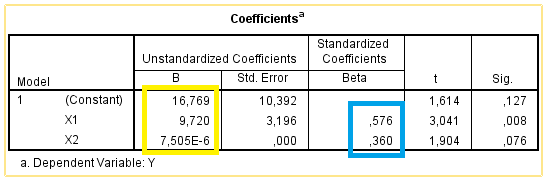
Hasil perhitungan menggunakan Excel dan SPSS sama kan Gaes….. tinggal kita pilih yang mana yang menurut kita mudah…… Selamat Belajar.

Min boleh nanya gak? Itu nilai SD pada tabel 2 dapat dari mana? Gimana cara nyarinya? Bisa jelaskan? Terimakasih
SukaSuka
Standar deviasi atau simpangan baku atau akar dari varians
SukaSuka
halo, apakah boleh tahu mengenai aturan Z-score dengan nilai kurang dari –3 atau lebih dari +3 mengacu dari jurnal atau buku yang mana? terima kasih sebelumnya
SukaSuka
TKS SANGAT MEMBANTU DALAM PEMBUATAN LAPORAN
SukaSuka